import tensorflow as tf
import tensorflow.experimental.numpy as tnp해당 강의노트는 전북대학교 최규빈교수님 STBDA2022 자료임
imports
tnp.experimental_enable_numpy_behavior()import matplotlib.pyplot as plt
import numpy as npCNN
CONV의 역할
- 데이터생성 (그냥 흑백대비 데이터)
_X1 = tnp.ones([50,25])*10
_X1<tf.Tensor: shape=(50, 25), dtype=float64, numpy=
array([[10., 10., 10., ..., 10., 10., 10.],
[10., 10., 10., ..., 10., 10., 10.],
[10., 10., 10., ..., 10., 10., 10.],
...,
[10., 10., 10., ..., 10., 10., 10.],
[10., 10., 10., ..., 10., 10., 10.],
[10., 10., 10., ..., 10., 10., 10.]])>_X2 = tnp.zeros([50,25])*10
_X2<tf.Tensor: shape=(50, 25), dtype=float64, numpy=
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])>tf.concat([_X1,_X2],axis=1)<tf.Tensor: shape=(50, 50), dtype=float64, numpy=
array([[10., 10., 10., ..., 0., 0., 0.],
[10., 10., 10., ..., 0., 0., 0.],
[10., 10., 10., ..., 0., 0., 0.],
...,
[10., 10., 10., ..., 0., 0., 0.],
[10., 10., 10., ..., 0., 0., 0.],
[10., 10., 10., ..., 0., 0., 0.]])>plt.imshow(tf.concat([_X1,_X2],axis=1),cmap='gray')<matplotlib.image.AxesImage at 0x7f6e504c5520> 5월23일_files/figure-html/cell-9-output-2.png)
_noise = tnp.random.randn(50*50).reshape(50,50)
_noise<tf.Tensor: shape=(50, 50), dtype=float64, numpy=
array([[ 0.17076016, 0.24556194, 0.67583537, ..., 0.66758916,
0.11793288, -0.40684891],
[ 1.24943253, 0.80192435, -0.10629932, ..., 0.19412642,
1.01308712, -0.51910469],
[-0.54708995, 1.32241983, 1.71576768, ..., -0.70771522,
-1.41728966, 1.29099964],
...,
[ 0.41993666, 0.01969409, -1.59803669, ..., -0.22710783,
1.10394856, -0.75150101],
[ 0.18437325, -0.18661286, -0.1701197 , ..., 0.15435531,
0.92806262, -1.19241476],
[ 0.20934349, 1.24031218, 1.52275298, ..., 0.41015174,
0.76922351, 1.74561576]])>XXX = tf.concat([_X1,_X2],axis=1) + _noiseXXX=XXX.reshape(1,50,50,1)plt.imshow(XXX.reshape(50,50),cmap='gray')<matplotlib.image.AxesImage at 0x7f6f0017f970> 5월23일_files/figure-html/cell-13-output-2.png)
- conv layer 생성
conv = tf.keras.layers.Conv2D(2,(2,2)) conv.weights # 처음에는 가중치가 없음 []conv(XXX) # 가중치를 만들기 위해서 XXX를 conv에 한번 통과시킴
conv.weights # 이제 가중치가 생김[<tf.Variable 'conv2d/kernel:0' shape=(2, 2, 1, 2) dtype=float32, numpy=
array([[[[ 0.12864834, -0.3870984 ]],
[[-0.4960475 , -0.09744334]]],
[[[ 0.38146013, -0.5358522 ]],
[[ 0.5728392 , -0.45205393]]]], dtype=float32)>,
<tf.Variable 'conv2d/bias:0' shape=(2,) dtype=float32, numpy=array([0., 0.], dtype=float32)>]- 가중치의 값을 확인해보자.
conv.weights[0] # kernel에 해당하는것 <tf.Variable 'conv2d/kernel:0' shape=(2, 2, 1, 2) dtype=float32, numpy=
array([[[[ 0.12864834, -0.3870984 ]],
[[-0.4960475 , -0.09744334]]],
[[[ 0.38146013, -0.5358522 ]],
[[ 0.5728392 , -0.45205393]]]], dtype=float32)>conv.weights[1] # bias에 해당하는것 <tf.Variable 'conv2d/bias:0' shape=(2,) dtype=float32, numpy=array([0., 0.], dtype=float32)>- 필터값을 원하는 것으로 변경해보자.
w0 = [[0.25,0.25],[0.25,0.25]] # 잡티(noise)를 제거하는 효과를 준다.
w1 = [[-1.0,1.0],[-1.0,1.0]] # 경계를 찾기 좋아보이는 필터이다. (엣지검출)w=np.concatenate([np.array(w0).reshape(2,2,1,1),np.array(w1).reshape(2,2,1,1)],axis=-1)
w # conv.weights[0] 의 디멘젼 (2,2,1,1)과 같이 만들기 위해서array([[[[ 0.25, -1. ]],
[[ 0.25, 1. ]]],
[[[ 0.25, -1. ]],
[[ 0.25, 1. ]]]])b= np.array([0.0,0.0])
barray([0., 0.])conv.set_weights([w,b])
conv.get_weights()[array([[[[ 0.25, -1. ]],
[[ 0.25, 1. ]]],
[[[ 0.25, -1. ]],
[[ 0.25, 1. ]]]], dtype=float32),
array([0., 0.], dtype=float32)]첫번째는 평균을 구하는 필터
두번째는 엣지를 검출하는 필터
- 필터를 넣은 결과를 확인
XXX0=conv(XXX)[...,0] # 채널0
XXX0<tf.Tensor: shape=(1, 49, 49), dtype=float32, numpy=
array([[[ 1.06169195e+01, 1.04042549e+01, 9.53252792e+00, ...,
1.73615709e-01, 4.98183906e-01, 5.12666255e-02],
[ 1.07066717e+01, 1.09334526e+01, 9.69403076e+00, ...,
-4.03259695e-03, -2.29447812e-01, 9.19231325e-02],
[ 9.95601559e+00, 1.03079481e+01, 1.01195173e+01, ...,
-1.59087405e-01, -1.04700661e+00, -8.29812646e-01],
...,
[ 1.03822594e+01, 9.66355324e+00, 9.83089066e+00, ...,
-3.26146245e-01, 5.32525420e-01, 4.50823545e-01],
[ 1.01093473e+01, 9.51623154e+00, 9.73521042e+00, ...,
-2.99041808e-01, 4.89814699e-01, 2.20238566e-02],
[ 1.03618546e+01, 1.06015835e+01, 1.05513611e+01, ...,
3.70336890e-01, 5.65448284e-01, 5.62621772e-01]]],
dtype=float32)>XXX1=conv(XXX)[...,1] # 채널1
XXX1<tf.Tensor: shape=(1, 49, 49), dtype=float32, numpy=
array([[[-0.37270737, -0.47794914, -3.0089607 , ..., 1.0289683 ,
0.2693045 , -2.0569737 ],
[ 1.4220009 , -0.5148754 , -4.442814 , ..., -1.0110471 ,
0.10938632, 1.1760974 ],
[ 1.1624336 , 0.24529648, -0.9990196 , ..., -0.8970997 ,
-2.6545773 , 3.523353 ],
...,
[-1.4986343 , -1.3761921 , 2.0455437 , ..., 2.929906 ,
0.5047808 , -0.8315882 ],
[-0.7712288 , -1.6012363 , 2.4771557 , ..., 1.0506623 ,
2.1047637 , -3.975927 ],
[ 0.6599827 , 0.29893494, -0.49982262, ..., -0.3523335 ,
1.1327791 , -1.1440852 ]]], dtype=float32)>- 각 채널을 시각화
fig, ((ax1,ax2),(ax3,ax4)) = plt.subplots(2,2) 5월23일_files/figure-html/cell-25-output-1.png)
ax1.imshow(XXX.reshape(50,50),cmap='gray')<matplotlib.image.AxesImage at 0x7f6de401ae50>ax3.imshow(XXX0.reshape(49,49),cmap='gray')<matplotlib.image.AxesImage at 0x7f6de41ac100>ax4.imshow(XXX1.reshape(49,49),cmap='gray')<matplotlib.image.AxesImage at 0x7f6e04214ee0>fig 5월23일_files/figure-html/cell-29-output-1.png)
2사분면: 원래이미지
3사분면: 원래이미지 -> 평균을 의미하는 conv적용
4사분면: 원래이미지 -> 엣지를 검출하는 conv적용
- conv(XXX)의 각 채널에 한번더 conv를 통과시켜보자
conv(XXX0.reshape(1,49,49,1))[...,0] ### XXX0 -> 평균필터 <=> XXX -> 평균필터 -> 평균필터
conv(XXX0.reshape(1,49,49,1))[...,1] ### XXX0 -> 엣지필터 <=> XXX -> 평균필터 -> 엣지필터
conv(XXX1.reshape(1,49,49,1))[...,0] ### XXX1 -> 평균필터 <=> XXX -> 엣지필터 -> 평균필터
conv(XXX1.reshape(1,49,49,1))[...,1] ### XXX1 -> 엣지필터 <=> XXX -> 엣지필터 -> 엣지필터 <tf.Tensor: shape=(1, 48, 48), dtype=float32, numpy=
array([[[-2.042118 , -6.45895 , 13.813332 , ..., 3.446345 ,
0.36076963, -1.2595671 ],
[-2.8540134 , -5.1722546 , 16.216526 , ..., 0.44306922,
-0.63704395, 7.2446413 ],
[-1.1664009 , 0.9689274 , 6.7377033 , ..., 3.0709298 ,
-7.5607853 , 10.2151375 ],
...,
[ 0.08633995, 3.5339375 , -3.587349 , ..., 6.584819 ,
-4.3739424 , 1.4463077 ],
[-0.7075653 , 7.500128 , -7.38381 , ..., 9.872438 ,
-1.3710237 , -7.41706 ],
[-1.1910553 , 3.2796345 , -6.0162563 , ..., 2.9223158 ,
2.5392141 , -8.357555 ]]], dtype=float32)>fig,ax =plt.subplots(3,4) 5월23일_files/figure-html/cell-31-output-1.png)
ax[0][0].imshow(XXX.reshape(50,50),cmap='gray') # 원래이미지<matplotlib.image.AxesImage at 0x7f6de401a430>ax[1][0].imshow(XXX0.reshape(49,49),cmap='gray') # 원래이미지 -> 평균필터
ax[1][2].imshow(XXX1.reshape(49,49),cmap='gray') # 원래이미지 -> 엣지필터<matplotlib.image.AxesImage at 0x7f6dc4e59f10>ax[2][0].imshow(conv(XXX0.reshape(1,49,49,1))[...,0].reshape(48,48),cmap='gray') # 원래이미지 -> 평균필터
ax[2][1].imshow(conv(XXX0.reshape(1,49,49,1))[...,1].reshape(48,48),cmap='gray') # 원래이미지 -> 엣지필터
ax[2][2].imshow(conv(XXX1.reshape(1,49,49,1))[...,0].reshape(48,48),cmap='gray') # 원래이미지 -> 평균필터
ax[2][3].imshow(conv(XXX1.reshape(1,49,49,1))[...,1].reshape(48,48),cmap='gray') # 원래이미지 -> 엣지필터<matplotlib.image.AxesImage at 0x7f6dc4ce0e20>fig.set_figheight(8)
fig.set_figwidth(16)
fig.tight_layout()
fig 5월23일_files/figure-html/cell-35-output-1.png)
- 요약 - conv의 weight에 따라서 엣지를 검출하는 필터가 만들어지기도 하고 스무딩의 역할을 하는 필터가 만들어지기도 한다. 그리고 우리는 의미를 알 수 없지만 어떠한 역할을 하는 필터가 만들어질 것이다. - 이것들을 조합하다보면 우연히 이미지를 분류하기에 유리한 특징을 뽑아내는 weight가 맞춰질 수도 있겠다. - 채널수를 많이 만들고 다양한 웨이트조합을 실험하다보면 보다 복잡한 이미지의 특징을 추출할 수도 있을 것이다? - 컨볼루션 레이어의 역할 = 이미지의 특징을 추출하는 역할
- 참고: 스트라이드, 패딩 - 스트라이드: 윈도우가 1칸씩 이동하는 것이 아니라 2~3칸씩 이동함 - 패딩: 이미지의 가장자리에 정당한 값을 넣어서 (예를들어 0) 컨볼루션을 수행. 따라서 컨볼루션 연산 이후에도 이미지의 크기가 줄어들지 않도록 방지한다.
MAXPOOL
- 기본적역할: 이미지의 크기를 줄이는 것
이미지의의 크기를 줄여야하는 이유? 어차피 최종적으로 10차원으로 줄어야하므로
이미지의 크기를 줄이면서도 동시에 아주 크리티컬한 특징은 손실없이 유지하고 싶다~
- 점점 작은 이미지가 되면서 중요한 특징들은 살아남지만 그렇지 않으면 죽는다. (캐리커쳐 느낌)
- 평균이 아니라 max를 쓴 이유는? 그냥 평균보다 나을것이라고 생각했음..
- 그런데 사실은 꼭 그렇지만은 않아서 최근에는 꼭 맥스풀링을 고집하진 않는 추세 (평균풀링도 많이씀)
CNN 아키텍처의 표현방법
- 아래와 같이 아키텍처의 다이어그램형태로 표현하고 굳이 노드별로 이미지를 그리진 않음

- 물론 아래와 같이 그리는 경우도 있음
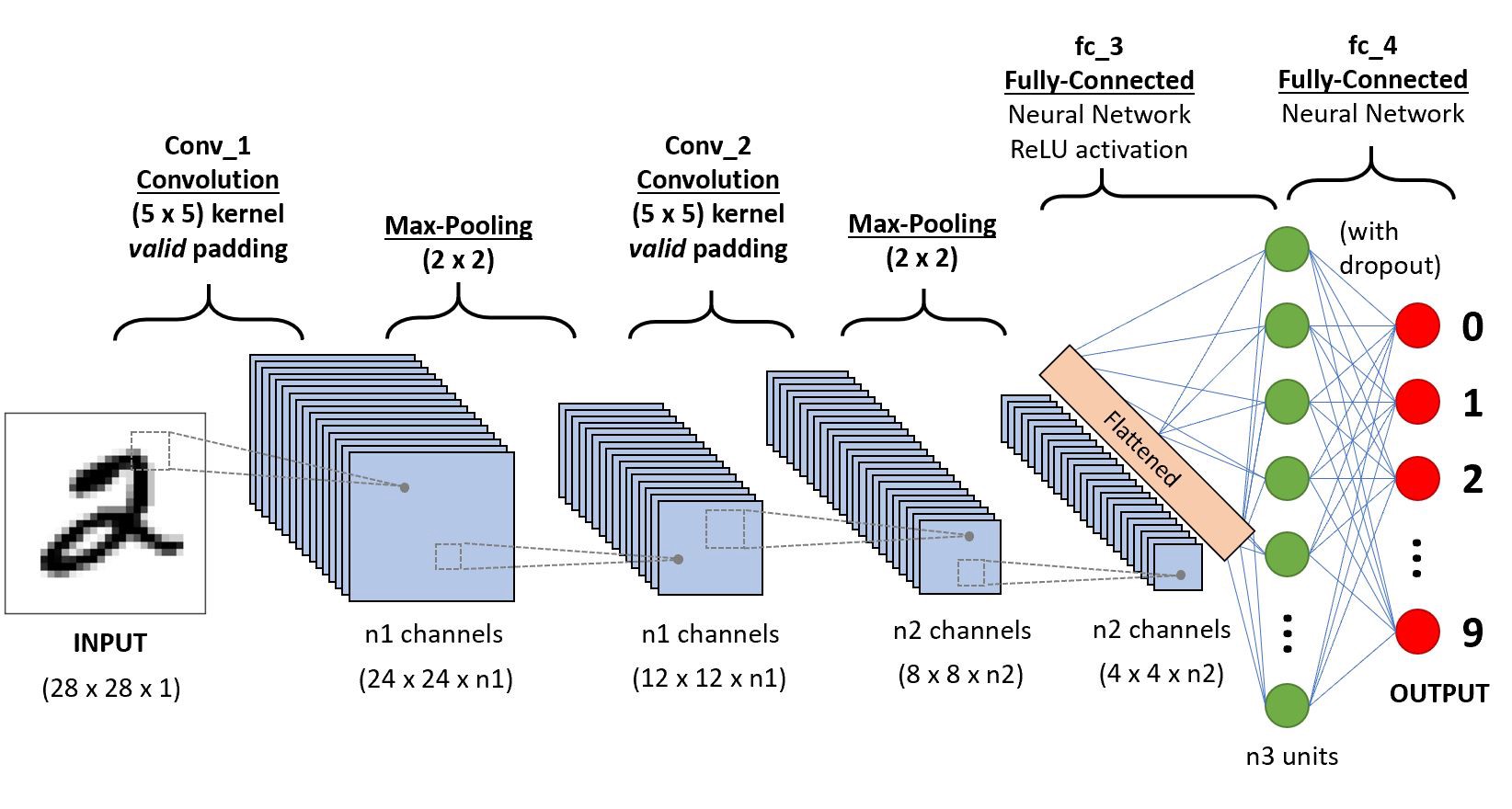
Discusstion about CNN
- 격자형태로 배열된 자료를 처리하는데 특화된 신경망이다.
- 시계열 (1차원격자), 이미지 (2차원격자)
- 실제응용에서 엄청난 성공을 거두었다.
- 이름의 유래는 컨볼루션이라는 수학적 연산을 사용했기 때문
- 컨볼루션은 조금 특별한 선형변환이다.
- 신경과학의 원리가 심층학습에 영향을 미친 사례이다.
CNN의 모티브
- 희소성 + 매개변수의 공유
다소 철학적인 모티브임
희소성: 이미지를 분석하여 특징을 뽑아낼때 부분부분의 특징만 뽑으면 된다는 의미
매개변수의 공유: 한 채널에는 하나의 역할을 하는 커널을 설계하면 된다는 의미 (스무딩이든 엣징이든). 즉 어떤지역은 스무딩, 어떤지역은 엣징을 할 필요가 없이 한채널에서는 엣징만, 다른채널에서는 스무딩만 수행한뒤 여러채널을 조합해서 이해하면 된다.
- 매개변수 공유효과로 인해서 파라메터가 확 줄어든다.
(예시) (1,6,6,1) -> (1,5,5,2)
MLP방식이면 (36,50) 의 차원을 가진 매트릭스가 필요함 => 1800개의 매개변수 필요
CNN은 8개의 매개변수 필요
CNN 신경망의 기본구조
- 기본유닛
conv - activation - pooling
conv - conv - activation - pooling
모형의 성능을 올리기 위한 노력들
dropout
- 아래의 예제를 복습하자.
np.random.seed(43052)
x = np.linspace(0,1,100).reshape(100,1)
y = np.random.normal(loc=0,scale=0.01,size=(100,1))
plt.plot(x,y) 5월23일_files/figure-html/cell-36-output-1.png)
tf.random.set_seed(43052)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(2048,activation='relu'))
net.add(tf.keras.layers.Dense(1))
net.compile(loss='mse',optimizer='adam')
net.fit(x,y,epochs=5000,verbose=0,batch_size=100)<keras.callbacks.History at 0x7f6dc4bd6760>plt.plot(x,y)
plt.plot(x,net(x),'--') 5월23일_files/figure-html/cell-38-output-1.png)
- train/test로 나누어서 생각해보자.
tf.random.set_seed(43052)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(2048,activation='relu'))
net.add(tf.keras.layers.Dense(1))
net.compile(loss='mse',optimizer='adam')
net.fit(x[:80],y[:80],epochs=5000,verbose=0,batch_size=80)<keras.callbacks.History at 0x7f6dc48eb0a0>plt.plot(x,y)
plt.plot(x[:80],net(x[:80]),'--') 5월23일_files/figure-html/cell-40-output-1.png)
plt.plot(x,y)
plt.plot(x[:80],net(x[:80]),'--')
plt.plot(x[80:],net(x[80:]),'--') 5월23일_files/figure-html/cell-41-output-1.png)
- train에서 추세를 따라가는게 좋은게 아니다 \(\to\) 그냥 직선으로 핏하는거 이외에는 다 오버핏이다.
- 매 에폭마다 적당히 80%의 노드들을 빼고 학습하자 \(\to\) 너무 잘 학습되는 문제는 생기지 않을 것이다 (과적합이 방지될것이다?)
tf.random.set_seed(43052)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(2048,activation='relu'))
net.add(tf.keras.layers.Dropout(0.8))
net.add(tf.keras.layers.Dense(1))
net.compile(loss='mse',optimizer='adam')
net.fit(x[:80],y[:80],epochs=5000,verbose=0,batch_size=80)<keras.callbacks.History at 0x7f6dc40380a0>plt.plot(x,y)
plt.plot(x[:80],net(x[:80]),'--')
plt.plot(x[80:],net(x[80:]),'--') 5월23일_files/figure-html/cell-43-output-1.png)
- 드랍아웃에 대한 summary
직관: 특정노드를 랜덤으로 off시키면 학습이 방해되어 오히려 과적합이 방지되는 효과가 있다 (그렇지만 진짜 중요한 특징이라면 랜덤으로 off 되더라도 어느정도는 학습될 듯)
note: 드랍아웃을 쓰면 오버핏이 줄어드는건 맞지만 완전히 없어지는건 아니다.
note: 오버핏을 줄이는 유일한 방법이 드랍아웃만 있는것도 아니며, 드랍아웃이 오버핏을 줄이는 가장 효과적인 방법도 아니다 (최근에는 dropout보다 batch nomalization을 사용하는 추세임)
train / val / test
- data
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()X= x_train.reshape(-1,28,28,1)/255 ## 입력이 0~255 -> 0~1로 표준화 시키는 효과 + float으로 자료형이 바뀜
y = tf.keras.utils.to_categorical(y_train)
XX = x_test.reshape(-1,28,28,1)/255
yy = tf.keras.utils.to_categorical(y_test)X.dtypedtype('float64')표준화하면 파라미터를 학습할 때 용이함
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(50,activation='relu'))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')validation_splitval을 0.2로
#collapse_output
cb1 = tf.keras.callbacks.TensorBoard()
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=cb1,verbose=1) Epoch 1/200
240/240 [==============================] - 1s 1ms/step - loss: 0.6794 - accuracy: 0.7736 - val_loss: 0.4910 - val_accuracy: 0.8310
Epoch 2/200
240/240 [==============================] - 0s 815us/step - loss: 0.4608 - accuracy: 0.8415 - val_loss: 0.4685 - val_accuracy: 0.8362
Epoch 3/200
240/240 [==============================] - 0s 799us/step - loss: 0.4217 - accuracy: 0.8520 - val_loss: 0.4349 - val_accuracy: 0.8491
Epoch 4/200
240/240 [==============================] - 0s 802us/step - loss: 0.4005 - accuracy: 0.8596 - val_loss: 0.4052 - val_accuracy: 0.8568
Epoch 5/200
240/240 [==============================] - 0s 817us/step - loss: 0.3790 - accuracy: 0.8669 - val_loss: 0.3915 - val_accuracy: 0.8632
Epoch 6/200
240/240 [==============================] - 0s 818us/step - loss: 0.3656 - accuracy: 0.8710 - val_loss: 0.3906 - val_accuracy: 0.8624
Epoch 7/200
240/240 [==============================] - 0s 802us/step - loss: 0.3542 - accuracy: 0.8743 - val_loss: 0.3905 - val_accuracy: 0.8640
Epoch 8/200
240/240 [==============================] - 0s 788us/step - loss: 0.3438 - accuracy: 0.8769 - val_loss: 0.3653 - val_accuracy: 0.8712
Epoch 9/200
240/240 [==============================] - 0s 815us/step - loss: 0.3366 - accuracy: 0.8814 - val_loss: 0.3601 - val_accuracy: 0.8741
Epoch 10/200
240/240 [==============================] - 0s 794us/step - loss: 0.3272 - accuracy: 0.8825 - val_loss: 0.3570 - val_accuracy: 0.8757
Epoch 11/200
240/240 [==============================] - 0s 812us/step - loss: 0.3188 - accuracy: 0.8861 - val_loss: 0.3588 - val_accuracy: 0.8737
Epoch 12/200
240/240 [==============================] - 0s 809us/step - loss: 0.3135 - accuracy: 0.8861 - val_loss: 0.3546 - val_accuracy: 0.8743
Epoch 13/200
240/240 [==============================] - 0s 813us/step - loss: 0.3067 - accuracy: 0.8894 - val_loss: 0.3595 - val_accuracy: 0.8757
Epoch 14/200
240/240 [==============================] - 0s 812us/step - loss: 0.3006 - accuracy: 0.8922 - val_loss: 0.3552 - val_accuracy: 0.8748
Epoch 15/200
240/240 [==============================] - 0s 804us/step - loss: 0.2985 - accuracy: 0.8924 - val_loss: 0.3571 - val_accuracy: 0.8744
Epoch 16/200
240/240 [==============================] - 0s 804us/step - loss: 0.2950 - accuracy: 0.8947 - val_loss: 0.3960 - val_accuracy: 0.8563
Epoch 17/200
240/240 [==============================] - 0s 801us/step - loss: 0.2890 - accuracy: 0.8958 - val_loss: 0.3461 - val_accuracy: 0.8783
Epoch 18/200
240/240 [==============================] - 0s 800us/step - loss: 0.2836 - accuracy: 0.8965 - val_loss: 0.3525 - val_accuracy: 0.8748
Epoch 19/200
240/240 [==============================] - 0s 821us/step - loss: 0.2802 - accuracy: 0.8976 - val_loss: 0.3502 - val_accuracy: 0.8783
Epoch 20/200
240/240 [==============================] - 0s 801us/step - loss: 0.2756 - accuracy: 0.8998 - val_loss: 0.3466 - val_accuracy: 0.8777
Epoch 21/200
240/240 [==============================] - 0s 817us/step - loss: 0.2735 - accuracy: 0.9005 - val_loss: 0.3424 - val_accuracy: 0.8790
Epoch 22/200
240/240 [==============================] - 0s 797us/step - loss: 0.2675 - accuracy: 0.9029 - val_loss: 0.3376 - val_accuracy: 0.8827
Epoch 23/200
240/240 [==============================] - 0s 806us/step - loss: 0.2637 - accuracy: 0.9031 - val_loss: 0.3444 - val_accuracy: 0.8793
Epoch 24/200
240/240 [==============================] - 0s 821us/step - loss: 0.2626 - accuracy: 0.9052 - val_loss: 0.3458 - val_accuracy: 0.8779
Epoch 25/200
240/240 [==============================] - 0s 795us/step - loss: 0.2556 - accuracy: 0.9074 - val_loss: 0.3401 - val_accuracy: 0.8816
Epoch 26/200
240/240 [==============================] - 0s 817us/step - loss: 0.2531 - accuracy: 0.9087 - val_loss: 0.3404 - val_accuracy: 0.8852
Epoch 27/200
240/240 [==============================] - 0s 813us/step - loss: 0.2517 - accuracy: 0.9086 - val_loss: 0.3423 - val_accuracy: 0.8832
Epoch 28/200
240/240 [==============================] - 0s 795us/step - loss: 0.2450 - accuracy: 0.9126 - val_loss: 0.3451 - val_accuracy: 0.8825
Epoch 29/200
240/240 [==============================] - 0s 794us/step - loss: 0.2464 - accuracy: 0.9101 - val_loss: 0.3477 - val_accuracy: 0.8788
Epoch 30/200
240/240 [==============================] - 0s 789us/step - loss: 0.2440 - accuracy: 0.9109 - val_loss: 0.3417 - val_accuracy: 0.8814
Epoch 31/200
240/240 [==============================] - 0s 792us/step - loss: 0.2394 - accuracy: 0.9136 - val_loss: 0.3442 - val_accuracy: 0.8796
Epoch 32/200
240/240 [==============================] - 0s 799us/step - loss: 0.2379 - accuracy: 0.9141 - val_loss: 0.3402 - val_accuracy: 0.8817
Epoch 33/200
240/240 [==============================] - 0s 796us/step - loss: 0.2360 - accuracy: 0.9148 - val_loss: 0.3585 - val_accuracy: 0.8792
Epoch 34/200
240/240 [==============================] - 0s 807us/step - loss: 0.2318 - accuracy: 0.9157 - val_loss: 0.3452 - val_accuracy: 0.8807
Epoch 35/200
240/240 [==============================] - 0s 790us/step - loss: 0.2292 - accuracy: 0.9178 - val_loss: 0.3570 - val_accuracy: 0.8763
Epoch 36/200
240/240 [==============================] - 0s 790us/step - loss: 0.2288 - accuracy: 0.9173 - val_loss: 0.3478 - val_accuracy: 0.8824
Epoch 37/200
240/240 [==============================] - 0s 795us/step - loss: 0.2252 - accuracy: 0.9193 - val_loss: 0.3505 - val_accuracy: 0.8836
Epoch 38/200
240/240 [==============================] - 0s 797us/step - loss: 0.2262 - accuracy: 0.9178 - val_loss: 0.3436 - val_accuracy: 0.8828
Epoch 39/200
240/240 [==============================] - 0s 782us/step - loss: 0.2213 - accuracy: 0.9201 - val_loss: 0.3394 - val_accuracy: 0.8846
Epoch 40/200
240/240 [==============================] - 0s 806us/step - loss: 0.2178 - accuracy: 0.9223 - val_loss: 0.3427 - val_accuracy: 0.8831
Epoch 41/200
240/240 [==============================] - 0s 789us/step - loss: 0.2145 - accuracy: 0.9232 - val_loss: 0.3548 - val_accuracy: 0.8798
Epoch 42/200
240/240 [==============================] - 0s 805us/step - loss: 0.2178 - accuracy: 0.9213 - val_loss: 0.3520 - val_accuracy: 0.8834
Epoch 43/200
240/240 [==============================] - 0s 796us/step - loss: 0.2137 - accuracy: 0.9223 - val_loss: 0.3565 - val_accuracy: 0.8803
Epoch 44/200
240/240 [==============================] - 0s 806us/step - loss: 0.2129 - accuracy: 0.9220 - val_loss: 0.3566 - val_accuracy: 0.8822
Epoch 45/200
240/240 [==============================] - 0s 791us/step - loss: 0.2065 - accuracy: 0.9254 - val_loss: 0.3483 - val_accuracy: 0.8830
Epoch 46/200
240/240 [==============================] - 0s 801us/step - loss: 0.2043 - accuracy: 0.9261 - val_loss: 0.3816 - val_accuracy: 0.8763
Epoch 47/200
240/240 [==============================] - 0s 804us/step - loss: 0.2078 - accuracy: 0.9247 - val_loss: 0.3576 - val_accuracy: 0.8793
Epoch 48/200
240/240 [==============================] - 0s 810us/step - loss: 0.1998 - accuracy: 0.9290 - val_loss: 0.3610 - val_accuracy: 0.8831
Epoch 49/200
240/240 [==============================] - 0s 816us/step - loss: 0.2015 - accuracy: 0.9267 - val_loss: 0.3578 - val_accuracy: 0.8813
Epoch 50/200
240/240 [==============================] - 0s 819us/step - loss: 0.1985 - accuracy: 0.9288 - val_loss: 0.3674 - val_accuracy: 0.8770
Epoch 51/200
240/240 [==============================] - 0s 798us/step - loss: 0.2012 - accuracy: 0.9274 - val_loss: 0.3534 - val_accuracy: 0.8827
Epoch 52/200
240/240 [==============================] - 0s 809us/step - loss: 0.1937 - accuracy: 0.9302 - val_loss: 0.3805 - val_accuracy: 0.8752
Epoch 53/200
240/240 [==============================] - 0s 793us/step - loss: 0.1926 - accuracy: 0.9311 - val_loss: 0.3702 - val_accuracy: 0.8786
Epoch 54/200
240/240 [==============================] - 0s 792us/step - loss: 0.1950 - accuracy: 0.9293 - val_loss: 0.3778 - val_accuracy: 0.8766
Epoch 55/200
240/240 [==============================] - 0s 790us/step - loss: 0.1914 - accuracy: 0.9316 - val_loss: 0.3700 - val_accuracy: 0.8774
Epoch 56/200
240/240 [==============================] - 0s 801us/step - loss: 0.1881 - accuracy: 0.9329 - val_loss: 0.3684 - val_accuracy: 0.8822
Epoch 57/200
240/240 [==============================] - 0s 815us/step - loss: 0.1883 - accuracy: 0.9324 - val_loss: 0.3698 - val_accuracy: 0.8809
Epoch 58/200
240/240 [==============================] - 0s 792us/step - loss: 0.1848 - accuracy: 0.9335 - val_loss: 0.3661 - val_accuracy: 0.8831
Epoch 59/200
240/240 [==============================] - 0s 809us/step - loss: 0.1860 - accuracy: 0.9332 - val_loss: 0.3744 - val_accuracy: 0.8783
Epoch 60/200
240/240 [==============================] - 0s 808us/step - loss: 0.1816 - accuracy: 0.9345 - val_loss: 0.3830 - val_accuracy: 0.8762
Epoch 61/200
240/240 [==============================] - 0s 798us/step - loss: 0.1801 - accuracy: 0.9351 - val_loss: 0.3805 - val_accuracy: 0.8779
Epoch 62/200
240/240 [==============================] - 0s 806us/step - loss: 0.1788 - accuracy: 0.9356 - val_loss: 0.3660 - val_accuracy: 0.8817
Epoch 63/200
240/240 [==============================] - 0s 806us/step - loss: 0.1803 - accuracy: 0.9348 - val_loss: 0.3693 - val_accuracy: 0.8814
Epoch 64/200
240/240 [==============================] - 0s 799us/step - loss: 0.1771 - accuracy: 0.9364 - val_loss: 0.3842 - val_accuracy: 0.8767
Epoch 65/200
240/240 [==============================] - 0s 795us/step - loss: 0.1738 - accuracy: 0.9385 - val_loss: 0.3977 - val_accuracy: 0.8768
Epoch 66/200
240/240 [==============================] - 0s 809us/step - loss: 0.1744 - accuracy: 0.9380 - val_loss: 0.3807 - val_accuracy: 0.8810
Epoch 67/200
240/240 [==============================] - 0s 808us/step - loss: 0.1727 - accuracy: 0.9379 - val_loss: 0.3881 - val_accuracy: 0.8790
Epoch 68/200
240/240 [==============================] - 0s 798us/step - loss: 0.1718 - accuracy: 0.9389 - val_loss: 0.3811 - val_accuracy: 0.8823
Epoch 69/200
240/240 [==============================] - 0s 796us/step - loss: 0.1711 - accuracy: 0.9389 - val_loss: 0.3894 - val_accuracy: 0.8768
Epoch 70/200
240/240 [==============================] - 0s 791us/step - loss: 0.1680 - accuracy: 0.9392 - val_loss: 0.3799 - val_accuracy: 0.8821
Epoch 71/200
240/240 [==============================] - 0s 791us/step - loss: 0.1683 - accuracy: 0.9392 - val_loss: 0.3839 - val_accuracy: 0.8804
Epoch 72/200
240/240 [==============================] - 0s 790us/step - loss: 0.1659 - accuracy: 0.9406 - val_loss: 0.3881 - val_accuracy: 0.8784
Epoch 73/200
240/240 [==============================] - 0s 802us/step - loss: 0.1628 - accuracy: 0.9424 - val_loss: 0.3856 - val_accuracy: 0.8808
Epoch 74/200
240/240 [==============================] - 0s 806us/step - loss: 0.1633 - accuracy: 0.9411 - val_loss: 0.3874 - val_accuracy: 0.8800
Epoch 75/200
240/240 [==============================] - 0s 804us/step - loss: 0.1621 - accuracy: 0.9426 - val_loss: 0.3862 - val_accuracy: 0.8814
Epoch 76/200
240/240 [==============================] - 0s 812us/step - loss: 0.1609 - accuracy: 0.9419 - val_loss: 0.4129 - val_accuracy: 0.8765
Epoch 77/200
240/240 [==============================] - 0s 792us/step - loss: 0.1586 - accuracy: 0.9434 - val_loss: 0.3877 - val_accuracy: 0.8788
Epoch 78/200
240/240 [==============================] - 0s 812us/step - loss: 0.1606 - accuracy: 0.9420 - val_loss: 0.4083 - val_accuracy: 0.8786
Epoch 79/200
240/240 [==============================] - 0s 806us/step - loss: 0.1581 - accuracy: 0.9442 - val_loss: 0.3989 - val_accuracy: 0.8801
Epoch 80/200
240/240 [==============================] - 0s 802us/step - loss: 0.1548 - accuracy: 0.9443 - val_loss: 0.4007 - val_accuracy: 0.8812
Epoch 81/200
240/240 [==============================] - 0s 787us/step - loss: 0.1536 - accuracy: 0.9462 - val_loss: 0.4037 - val_accuracy: 0.8779
Epoch 82/200
240/240 [==============================] - 0s 809us/step - loss: 0.1531 - accuracy: 0.9451 - val_loss: 0.4085 - val_accuracy: 0.8776
Epoch 83/200
240/240 [==============================] - 0s 795us/step - loss: 0.1521 - accuracy: 0.9455 - val_loss: 0.4313 - val_accuracy: 0.8749
Epoch 84/200
240/240 [==============================] - 0s 808us/step - loss: 0.1488 - accuracy: 0.9465 - val_loss: 0.4161 - val_accuracy: 0.8751
Epoch 85/200
240/240 [==============================] - 0s 803us/step - loss: 0.1491 - accuracy: 0.9465 - val_loss: 0.4109 - val_accuracy: 0.8764
Epoch 86/200
240/240 [==============================] - 0s 816us/step - loss: 0.1526 - accuracy: 0.9446 - val_loss: 0.4114 - val_accuracy: 0.8789
Epoch 87/200
240/240 [==============================] - 0s 794us/step - loss: 0.1466 - accuracy: 0.9483 - val_loss: 0.4237 - val_accuracy: 0.8760
Epoch 88/200
240/240 [==============================] - 0s 786us/step - loss: 0.1464 - accuracy: 0.9477 - val_loss: 0.4202 - val_accuracy: 0.8776
Epoch 89/200
240/240 [==============================] - 0s 788us/step - loss: 0.1486 - accuracy: 0.9467 - val_loss: 0.4262 - val_accuracy: 0.8784
Epoch 90/200
240/240 [==============================] - 0s 793us/step - loss: 0.1495 - accuracy: 0.9461 - val_loss: 0.4205 - val_accuracy: 0.8778
Epoch 91/200
240/240 [==============================] - 0s 790us/step - loss: 0.1407 - accuracy: 0.9504 - val_loss: 0.4134 - val_accuracy: 0.8804
Epoch 92/200
240/240 [==============================] - 0s 805us/step - loss: 0.1441 - accuracy: 0.9483 - val_loss: 0.4205 - val_accuracy: 0.8812
Epoch 93/200
240/240 [==============================] - 0s 805us/step - loss: 0.1440 - accuracy: 0.9496 - val_loss: 0.4224 - val_accuracy: 0.8789
Epoch 94/200
240/240 [==============================] - 0s 820us/step - loss: 0.1426 - accuracy: 0.9492 - val_loss: 0.4261 - val_accuracy: 0.8792
Epoch 95/200
240/240 [==============================] - 0s 807us/step - loss: 0.1418 - accuracy: 0.9501 - val_loss: 0.4332 - val_accuracy: 0.8779
Epoch 96/200
240/240 [==============================] - 0s 812us/step - loss: 0.1381 - accuracy: 0.9503 - val_loss: 0.4334 - val_accuracy: 0.8767
Epoch 97/200
240/240 [==============================] - 0s 811us/step - loss: 0.1378 - accuracy: 0.9511 - val_loss: 0.4355 - val_accuracy: 0.8788
Epoch 98/200
240/240 [==============================] - 0s 805us/step - loss: 0.1347 - accuracy: 0.9531 - val_loss: 0.4274 - val_accuracy: 0.8752
Epoch 99/200
240/240 [==============================] - 0s 826us/step - loss: 0.1358 - accuracy: 0.9521 - val_loss: 0.4296 - val_accuracy: 0.8775
Epoch 100/200
240/240 [==============================] - 0s 807us/step - loss: 0.1369 - accuracy: 0.9515 - val_loss: 0.4329 - val_accuracy: 0.8777
Epoch 101/200
240/240 [==============================] - 0s 802us/step - loss: 0.1319 - accuracy: 0.9531 - val_loss: 0.4352 - val_accuracy: 0.8772
Epoch 102/200
240/240 [==============================] - 0s 788us/step - loss: 0.1363 - accuracy: 0.9519 - val_loss: 0.4417 - val_accuracy: 0.8784
Epoch 103/200
240/240 [==============================] - 0s 793us/step - loss: 0.1334 - accuracy: 0.9528 - val_loss: 0.4410 - val_accuracy: 0.8780
Epoch 104/200
240/240 [==============================] - 0s 809us/step - loss: 0.1330 - accuracy: 0.9526 - val_loss: 0.4424 - val_accuracy: 0.8771
Epoch 105/200
240/240 [==============================] - 0s 807us/step - loss: 0.1339 - accuracy: 0.9524 - val_loss: 0.4622 - val_accuracy: 0.8724
Epoch 106/200
240/240 [==============================] - 0s 814us/step - loss: 0.1313 - accuracy: 0.9535 - val_loss: 0.4406 - val_accuracy: 0.8803
Epoch 107/200
240/240 [==============================] - 0s 803us/step - loss: 0.1299 - accuracy: 0.9541 - val_loss: 0.4748 - val_accuracy: 0.8723
Epoch 108/200
240/240 [==============================] - 0s 812us/step - loss: 0.1278 - accuracy: 0.9551 - val_loss: 0.4593 - val_accuracy: 0.8742
Epoch 109/200
240/240 [==============================] - 0s 826us/step - loss: 0.1288 - accuracy: 0.9551 - val_loss: 0.4564 - val_accuracy: 0.8758
Epoch 110/200
240/240 [==============================] - 0s 799us/step - loss: 0.1268 - accuracy: 0.9551 - val_loss: 0.4547 - val_accuracy: 0.8758
Epoch 111/200
240/240 [==============================] - 0s 810us/step - loss: 0.1293 - accuracy: 0.9544 - val_loss: 0.4526 - val_accuracy: 0.8778
Epoch 112/200
240/240 [==============================] - 0s 810us/step - loss: 0.1280 - accuracy: 0.9550 - val_loss: 0.4563 - val_accuracy: 0.8777
Epoch 113/200
240/240 [==============================] - 0s 798us/step - loss: 0.1253 - accuracy: 0.9555 - val_loss: 0.4629 - val_accuracy: 0.8762
Epoch 114/200
240/240 [==============================] - 0s 804us/step - loss: 0.1229 - accuracy: 0.9569 - val_loss: 0.4688 - val_accuracy: 0.8764
Epoch 115/200
240/240 [==============================] - 0s 794us/step - loss: 0.1215 - accuracy: 0.9577 - val_loss: 0.4664 - val_accuracy: 0.8737
Epoch 116/200
240/240 [==============================] - 0s 804us/step - loss: 0.1198 - accuracy: 0.9579 - val_loss: 0.4675 - val_accuracy: 0.8751
Epoch 117/200
240/240 [==============================] - 0s 801us/step - loss: 0.1209 - accuracy: 0.9581 - val_loss: 0.4704 - val_accuracy: 0.8758
Epoch 118/200
240/240 [==============================] - 0s 788us/step - loss: 0.1207 - accuracy: 0.9574 - val_loss: 0.4779 - val_accuracy: 0.8752
Epoch 119/200
240/240 [==============================] - 0s 795us/step - loss: 0.1222 - accuracy: 0.9572 - val_loss: 0.5012 - val_accuracy: 0.8697
Epoch 120/200
240/240 [==============================] - 0s 806us/step - loss: 0.1197 - accuracy: 0.9581 - val_loss: 0.4750 - val_accuracy: 0.8757
Epoch 121/200
240/240 [==============================] - 0s 806us/step - loss: 0.1185 - accuracy: 0.9585 - val_loss: 0.4926 - val_accuracy: 0.8737
Epoch 122/200
240/240 [==============================] - 0s 819us/step - loss: 0.1161 - accuracy: 0.9594 - val_loss: 0.4891 - val_accuracy: 0.8717
Epoch 123/200
240/240 [==============================] - 0s 804us/step - loss: 0.1175 - accuracy: 0.9584 - val_loss: 0.4745 - val_accuracy: 0.8765
Epoch 124/200
240/240 [==============================] - 0s 812us/step - loss: 0.1187 - accuracy: 0.9590 - val_loss: 0.4990 - val_accuracy: 0.8714
Epoch 125/200
240/240 [==============================] - 0s 819us/step - loss: 0.1140 - accuracy: 0.9605 - val_loss: 0.4990 - val_accuracy: 0.8748
Epoch 126/200
240/240 [==============================] - 0s 822us/step - loss: 0.1160 - accuracy: 0.9590 - val_loss: 0.5139 - val_accuracy: 0.8716
Epoch 127/200
240/240 [==============================] - 0s 815us/step - loss: 0.1158 - accuracy: 0.9586 - val_loss: 0.4926 - val_accuracy: 0.8773
Epoch 128/200
240/240 [==============================] - 0s 806us/step - loss: 0.1104 - accuracy: 0.9624 - val_loss: 0.4994 - val_accuracy: 0.8731
Epoch 129/200
240/240 [==============================] - 0s 799us/step - loss: 0.1134 - accuracy: 0.9603 - val_loss: 0.4956 - val_accuracy: 0.8759
Epoch 130/200
240/240 [==============================] - 0s 799us/step - loss: 0.1082 - accuracy: 0.9619 - val_loss: 0.5080 - val_accuracy: 0.8727
Epoch 131/200
240/240 [==============================] - 0s 806us/step - loss: 0.1110 - accuracy: 0.9605 - val_loss: 0.5051 - val_accuracy: 0.8722
Epoch 132/200
240/240 [==============================] - 0s 783us/step - loss: 0.1135 - accuracy: 0.9596 - val_loss: 0.5060 - val_accuracy: 0.8714
Epoch 133/200
240/240 [==============================] - 0s 794us/step - loss: 0.1125 - accuracy: 0.9607 - val_loss: 0.5162 - val_accuracy: 0.8706
Epoch 134/200
240/240 [==============================] - 0s 817us/step - loss: 0.1064 - accuracy: 0.9627 - val_loss: 0.5018 - val_accuracy: 0.8744
Epoch 135/200
240/240 [==============================] - 0s 822us/step - loss: 0.1084 - accuracy: 0.9614 - val_loss: 0.5090 - val_accuracy: 0.8728
Epoch 136/200
240/240 [==============================] - 0s 808us/step - loss: 0.1054 - accuracy: 0.9637 - val_loss: 0.5060 - val_accuracy: 0.8763
Epoch 137/200
240/240 [==============================] - 0s 812us/step - loss: 0.1083 - accuracy: 0.9618 - val_loss: 0.5197 - val_accuracy: 0.8752
Epoch 138/200
240/240 [==============================] - 0s 824us/step - loss: 0.1082 - accuracy: 0.9625 - val_loss: 0.5108 - val_accuracy: 0.8738
Epoch 139/200
240/240 [==============================] - 0s 815us/step - loss: 0.1064 - accuracy: 0.9623 - val_loss: 0.5169 - val_accuracy: 0.8754
Epoch 140/200
240/240 [==============================] - 0s 821us/step - loss: 0.1053 - accuracy: 0.9627 - val_loss: 0.5307 - val_accuracy: 0.8748
Epoch 141/200
240/240 [==============================] - 0s 820us/step - loss: 0.1062 - accuracy: 0.9625 - val_loss: 0.5226 - val_accuracy: 0.8748
Epoch 142/200
240/240 [==============================] - 0s 808us/step - loss: 0.1091 - accuracy: 0.9611 - val_loss: 0.5308 - val_accuracy: 0.8731
Epoch 143/200
240/240 [==============================] - 0s 816us/step - loss: 0.1058 - accuracy: 0.9641 - val_loss: 0.5271 - val_accuracy: 0.8725
Epoch 144/200
240/240 [==============================] - 0s 806us/step - loss: 0.1026 - accuracy: 0.9644 - val_loss: 0.5439 - val_accuracy: 0.8740
Epoch 145/200
240/240 [==============================] - 0s 815us/step - loss: 0.1002 - accuracy: 0.9661 - val_loss: 0.5382 - val_accuracy: 0.8735
Epoch 146/200
240/240 [==============================] - 0s 814us/step - loss: 0.1039 - accuracy: 0.9636 - val_loss: 0.5334 - val_accuracy: 0.8730
Epoch 147/200
240/240 [==============================] - 0s 813us/step - loss: 0.1007 - accuracy: 0.9657 - val_loss: 0.5416 - val_accuracy: 0.8739
Epoch 148/200
240/240 [==============================] - 0s 788us/step - loss: 0.1025 - accuracy: 0.9644 - val_loss: 0.5343 - val_accuracy: 0.8755
Epoch 149/200
240/240 [==============================] - 0s 817us/step - loss: 0.1014 - accuracy: 0.9648 - val_loss: 0.5390 - val_accuracy: 0.8736
Epoch 150/200
240/240 [==============================] - 0s 804us/step - loss: 0.1016 - accuracy: 0.9644 - val_loss: 0.5470 - val_accuracy: 0.8742
Epoch 151/200
240/240 [==============================] - 0s 818us/step - loss: 0.0989 - accuracy: 0.9656 - val_loss: 0.5455 - val_accuracy: 0.8761
Epoch 152/200
240/240 [==============================] - 0s 799us/step - loss: 0.1004 - accuracy: 0.9642 - val_loss: 0.5531 - val_accuracy: 0.8740
Epoch 153/200
240/240 [==============================] - 0s 808us/step - loss: 0.0975 - accuracy: 0.9654 - val_loss: 0.5628 - val_accuracy: 0.8687
Epoch 154/200
240/240 [==============================] - 0s 808us/step - loss: 0.0981 - accuracy: 0.9665 - val_loss: 0.5476 - val_accuracy: 0.8741
Epoch 155/200
240/240 [==============================] - 0s 821us/step - loss: 0.0976 - accuracy: 0.9661 - val_loss: 0.5558 - val_accuracy: 0.8747
Epoch 156/200
240/240 [==============================] - 0s 806us/step - loss: 0.0978 - accuracy: 0.9661 - val_loss: 0.5666 - val_accuracy: 0.8750
Epoch 157/200
240/240 [==============================] - 0s 808us/step - loss: 0.0954 - accuracy: 0.9674 - val_loss: 0.5755 - val_accuracy: 0.8708
Epoch 158/200
240/240 [==============================] - 0s 822us/step - loss: 0.0962 - accuracy: 0.9661 - val_loss: 0.5584 - val_accuracy: 0.8737
Epoch 159/200
240/240 [==============================] - 0s 788us/step - loss: 0.0970 - accuracy: 0.9656 - val_loss: 0.5821 - val_accuracy: 0.8707
Epoch 160/200
240/240 [==============================] - 0s 812us/step - loss: 0.0914 - accuracy: 0.9693 - val_loss: 0.5705 - val_accuracy: 0.8731
Epoch 161/200
240/240 [==============================] - 0s 799us/step - loss: 0.0985 - accuracy: 0.9644 - val_loss: 0.5941 - val_accuracy: 0.8702
Epoch 162/200
240/240 [==============================] - 0s 812us/step - loss: 0.0925 - accuracy: 0.9676 - val_loss: 0.5597 - val_accuracy: 0.8742
Epoch 163/200
240/240 [==============================] - 0s 819us/step - loss: 0.0917 - accuracy: 0.9687 - val_loss: 0.5687 - val_accuracy: 0.8735
Epoch 164/200
240/240 [==============================] - 0s 798us/step - loss: 0.0949 - accuracy: 0.9668 - val_loss: 0.5754 - val_accuracy: 0.8726
Epoch 165/200
240/240 [==============================] - 0s 813us/step - loss: 0.0897 - accuracy: 0.9697 - val_loss: 0.5657 - val_accuracy: 0.8748
Epoch 166/200
240/240 [==============================] - 0s 802us/step - loss: 0.0940 - accuracy: 0.9679 - val_loss: 0.5834 - val_accuracy: 0.8741
Epoch 167/200
240/240 [==============================] - 0s 796us/step - loss: 0.0900 - accuracy: 0.9686 - val_loss: 0.5859 - val_accuracy: 0.8726
Epoch 168/200
240/240 [==============================] - 0s 813us/step - loss: 0.0936 - accuracy: 0.9674 - val_loss: 0.5875 - val_accuracy: 0.8743
Epoch 169/200
240/240 [==============================] - 0s 813us/step - loss: 0.0897 - accuracy: 0.9680 - val_loss: 0.5895 - val_accuracy: 0.8723
Epoch 170/200
240/240 [==============================] - 0s 811us/step - loss: 0.0902 - accuracy: 0.9694 - val_loss: 0.5747 - val_accuracy: 0.8746
Epoch 171/200
240/240 [==============================] - 0s 805us/step - loss: 0.0883 - accuracy: 0.9695 - val_loss: 0.5907 - val_accuracy: 0.8733
Epoch 172/200
240/240 [==============================] - 0s 806us/step - loss: 0.0894 - accuracy: 0.9689 - val_loss: 0.6095 - val_accuracy: 0.8688
Epoch 173/200
240/240 [==============================] - 0s 820us/step - loss: 0.0867 - accuracy: 0.9701 - val_loss: 0.5941 - val_accuracy: 0.8715
Epoch 174/200
240/240 [==============================] - 0s 820us/step - loss: 0.0857 - accuracy: 0.9709 - val_loss: 0.6018 - val_accuracy: 0.8723
Epoch 175/200
240/240 [==============================] - 0s 806us/step - loss: 0.0879 - accuracy: 0.9698 - val_loss: 0.6147 - val_accuracy: 0.8708
Epoch 176/200
240/240 [==============================] - 0s 814us/step - loss: 0.0879 - accuracy: 0.9694 - val_loss: 0.6056 - val_accuracy: 0.8727
Epoch 177/200
240/240 [==============================] - 0s 827us/step - loss: 0.0880 - accuracy: 0.9689 - val_loss: 0.5992 - val_accuracy: 0.8748
Epoch 178/200
240/240 [==============================] - 0s 811us/step - loss: 0.0860 - accuracy: 0.9699 - val_loss: 0.6020 - val_accuracy: 0.8721
Epoch 179/200
240/240 [==============================] - 0s 796us/step - loss: 0.0855 - accuracy: 0.9708 - val_loss: 0.6206 - val_accuracy: 0.8705
Epoch 180/200
240/240 [==============================] - 0s 797us/step - loss: 0.0869 - accuracy: 0.9697 - val_loss: 0.6087 - val_accuracy: 0.8749
Epoch 181/200
240/240 [==============================] - 0s 810us/step - loss: 0.0919 - accuracy: 0.9678 - val_loss: 0.6212 - val_accuracy: 0.8709
Epoch 182/200
240/240 [==============================] - 0s 801us/step - loss: 0.0852 - accuracy: 0.9710 - val_loss: 0.6057 - val_accuracy: 0.8740
Epoch 183/200
240/240 [==============================] - 0s 810us/step - loss: 0.0830 - accuracy: 0.9720 - val_loss: 0.6209 - val_accuracy: 0.8707
Epoch 184/200
240/240 [==============================] - 0s 820us/step - loss: 0.0811 - accuracy: 0.9730 - val_loss: 0.6288 - val_accuracy: 0.8722
Epoch 185/200
240/240 [==============================] - 0s 808us/step - loss: 0.0847 - accuracy: 0.9700 - val_loss: 0.6498 - val_accuracy: 0.8694
Epoch 186/200
240/240 [==============================] - 0s 813us/step - loss: 0.0851 - accuracy: 0.9702 - val_loss: 0.6333 - val_accuracy: 0.8733
Epoch 187/200
240/240 [==============================] - 0s 810us/step - loss: 0.0827 - accuracy: 0.9716 - val_loss: 0.6300 - val_accuracy: 0.8734
Epoch 188/200
240/240 [==============================] - 0s 796us/step - loss: 0.0841 - accuracy: 0.9713 - val_loss: 0.6223 - val_accuracy: 0.8733
Epoch 189/200
240/240 [==============================] - 0s 830us/step - loss: 0.0866 - accuracy: 0.9702 - val_loss: 0.6512 - val_accuracy: 0.8692
Epoch 190/200
240/240 [==============================] - 0s 787us/step - loss: 0.0820 - accuracy: 0.9718 - val_loss: 0.6240 - val_accuracy: 0.8725
Epoch 191/200
240/240 [==============================] - 0s 807us/step - loss: 0.0777 - accuracy: 0.9738 - val_loss: 0.6435 - val_accuracy: 0.8706
Epoch 192/200
240/240 [==============================] - 0s 821us/step - loss: 0.0776 - accuracy: 0.9746 - val_loss: 0.6375 - val_accuracy: 0.8732
Epoch 193/200
240/240 [==============================] - 0s 806us/step - loss: 0.0776 - accuracy: 0.9735 - val_loss: 0.6398 - val_accuracy: 0.8725
Epoch 194/200
240/240 [==============================] - 0s 794us/step - loss: 0.0829 - accuracy: 0.9714 - val_loss: 0.6403 - val_accuracy: 0.8706
Epoch 195/200
240/240 [==============================] - 0s 817us/step - loss: 0.0774 - accuracy: 0.9732 - val_loss: 0.6408 - val_accuracy: 0.8734
Epoch 196/200
240/240 [==============================] - 0s 824us/step - loss: 0.0789 - accuracy: 0.9729 - val_loss: 0.6458 - val_accuracy: 0.8701
Epoch 197/200
240/240 [==============================] - 0s 814us/step - loss: 0.0781 - accuracy: 0.9732 - val_loss: 0.6451 - val_accuracy: 0.8712
Epoch 198/200
240/240 [==============================] - 0s 817us/step - loss: 0.0817 - accuracy: 0.9715 - val_loss: 0.6450 - val_accuracy: 0.8699
Epoch 199/200
240/240 [==============================] - 0s 821us/step - loss: 0.0783 - accuracy: 0.9727 - val_loss: 0.6496 - val_accuracy: 0.8720
Epoch 200/200
240/240 [==============================] - 0s 815us/step - loss: 0.0789 - accuracy: 0.9730 - val_loss: 0.6477 - val_accuracy: 0.8722<keras.callbacks.History at 0x7f6da1afa280>- 텐서보드 여는 방법1
%load_ext tensorboard
# 주피터노트북 (혹은 주피터랩)에서 텐서보드를 임베딩하여 넣을 수 있도록 도와주는 매직펑션#
# !rm -rf logs
# !kill 313799#
# %tensorboard --logdir logs --host 0.0.0.0
# %tensorboard --logdir logs # <-- 실습에서는 이렇게 하면됩니다. (참고사항) 파이썬 3.10의 경우 아래의 수정이 필요
?/python3.10/site-packages/tensorboard/_vendor/html5lib/_trie/_base.py 을 열고
from collections import Mapping ### 수정전
from collections.abc import Mapping ### 수정후 와 같이 수정한다.
- 왜냐하면 파이썬 3.10부터
from collections import Mapping가 동작하지 않고from collections.abc import Mapping가 동작하도록 문법이 바뀜
- 텐서보드를 실행하는 방법2
#
# !tensorboard --logdir logs --host 0.0.0.0
# !tensorboard --logdir logs # <-- 실습에서는 이렇게 하면됩니다. 조기종료
- 텐서보드를 살펴보니 특정에폭 이후에는 오히려 과적합이 진행되는 듯 하다 (학습할수록 손해인듯 하다) \(\to\) 그 특정에폭까지만 학습해보자
tf.random.set_seed(43052)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(5000,activation='relu')) ## 과적합좀 시키려고
net.add(tf.keras.layers.Dense(5000,activation='relu')) ## 레이어를 2장만듬 + 레이어하나당 노드수도 증가
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')#
#cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=1) # val-loss가 1회증가하면 멈추어라
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=cb2,verbose=1) Epoch 1/200
240/240 [==============================] - 1s 4ms/step - loss: 0.5483 - accuracy: 0.8134 - val_loss: 0.4027 - val_accuracy: 0.8546
Epoch 2/200
240/240 [==============================] - 1s 3ms/step - loss: 0.3568 - accuracy: 0.8671 - val_loss: 0.3531 - val_accuracy: 0.8712
Epoch 3/200
240/240 [==============================] - 1s 3ms/step - loss: 0.3210 - accuracy: 0.8799 - val_loss: 0.3477 - val_accuracy: 0.8733
Epoch 4/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2971 - accuracy: 0.8876 - val_loss: 0.3502 - val_accuracy: 0.8776<keras.callbacks.History at 0x7f1b80086650>#
#cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=1) # val-loss가 1회증가하면 멈추어라
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=cb2,verbose=1) Epoch 1/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2791 - accuracy: 0.8935 - val_loss: 0.3224 - val_accuracy: 0.8820
Epoch 2/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2619 - accuracy: 0.8999 - val_loss: 0.3498 - val_accuracy: 0.8779<keras.callbacks.History at 0x7f1b24290a90>#
#cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=1) # val-loss가 1회증가하면 멈추어라
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=cb2,verbose=1) Epoch 1/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2491 - accuracy: 0.9043 - val_loss: 0.3641 - val_accuracy: 0.8711
Epoch 2/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2328 - accuracy: 0.9110 - val_loss: 0.3282 - val_accuracy: 0.8848
Epoch 3/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2254 - accuracy: 0.9151 - val_loss: 0.3280 - val_accuracy: 0.8843
Epoch 4/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2144 - accuracy: 0.9177 - val_loss: 0.3191 - val_accuracy: 0.8925
Epoch 5/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2074 - accuracy: 0.9223 - val_loss: 0.3152 - val_accuracy: 0.8949
Epoch 6/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1952 - accuracy: 0.9250 - val_loss: 0.3322 - val_accuracy: 0.8863<keras.callbacks.History at 0x7f1b242c1660>#
#cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=1) # val-loss가 1회증가하면 멈추어라
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=cb2,verbose=1) Epoch 1/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1908 - accuracy: 0.9257 - val_loss: 0.3513 - val_accuracy: 0.8836
Epoch 2/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1799 - accuracy: 0.9304 - val_loss: 0.3376 - val_accuracy: 0.8901
Epoch 3/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1712 - accuracy: 0.9346 - val_loss: 0.3568 - val_accuracy: 0.8894<keras.callbacks.History at 0x7f1b24302230>#
#cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=1) # val-loss가 1회증가하면 멈추어라
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=cb2,verbose=1) Epoch 1/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1591 - accuracy: 0.9367 - val_loss: 0.3995 - val_accuracy: 0.8780
Epoch 2/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1552 - accuracy: 0.9398 - val_loss: 0.3469 - val_accuracy: 0.8917
Epoch 3/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1481 - accuracy: 0.9423 - val_loss: 0.3726 - val_accuracy: 0.8853<keras.callbacks.History at 0x7f1b24136e00>- 몇 번 좀 참았다가 멈추면 좋겠다.
tf.random.set_seed(43052)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(5000,activation='relu')) ## 과적합좀 시키려고
net.add(tf.keras.layers.Dense(5000,activation='relu')) ## 레이어를 2장만듬 + 레이어하나당 노드수도 증가
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')#
#cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=5) # 좀더 참다가 멈추어라
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=cb2,verbose=1) Epoch 1/200
240/240 [==============================] - 1s 4ms/step - loss: 0.5475 - accuracy: 0.8139 - val_loss: 0.4219 - val_accuracy: 0.8453
Epoch 2/200
240/240 [==============================] - 1s 3ms/step - loss: 0.3575 - accuracy: 0.8676 - val_loss: 0.3647 - val_accuracy: 0.8712
Epoch 3/200
240/240 [==============================] - 1s 3ms/step - loss: 0.3219 - accuracy: 0.8792 - val_loss: 0.3559 - val_accuracy: 0.8710
Epoch 4/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2990 - accuracy: 0.8883 - val_loss: 0.3448 - val_accuracy: 0.8808
Epoch 5/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2759 - accuracy: 0.8966 - val_loss: 0.3337 - val_accuracy: 0.8792
Epoch 6/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2621 - accuracy: 0.9004 - val_loss: 0.3220 - val_accuracy: 0.8841
Epoch 7/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2478 - accuracy: 0.9074 - val_loss: 0.3302 - val_accuracy: 0.8858
Epoch 8/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2342 - accuracy: 0.9110 - val_loss: 0.3150 - val_accuracy: 0.8904
Epoch 9/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2261 - accuracy: 0.9144 - val_loss: 0.3117 - val_accuracy: 0.8932
Epoch 10/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2116 - accuracy: 0.9200 - val_loss: 0.3345 - val_accuracy: 0.8888
Epoch 11/200
240/240 [==============================] - 1s 3ms/step - loss: 0.2081 - accuracy: 0.9207 - val_loss: 0.3344 - val_accuracy: 0.8867
Epoch 12/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1956 - accuracy: 0.9255 - val_loss: 0.3158 - val_accuracy: 0.8975
Epoch 13/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1863 - accuracy: 0.9275 - val_loss: 0.3302 - val_accuracy: 0.8934
Epoch 14/200
240/240 [==============================] - 1s 3ms/step - loss: 0.1764 - accuracy: 0.9324 - val_loss: 0.3717 - val_accuracy: 0.8859<keras.callbacks.History at 0x7f1b24301960>- 텐서보드로 그려보자?
#
# %tensorboard --logdir logs --host 0.0.0.0
# 아무것도 안나온다 -> 왜? cb1을 써야 텐서보드가 나옴- 조기종료와 텐서보드를 같이 쓰려면?
tf.random.set_seed(43052)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(50,activation='relu'))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics='accuracy')callback에 cb1, cb2,를 리스트로 같이 전달하면 된다.
cb1 = tf.keras.callbacks.TensorBoard()
cb2 = tf.keras.callbacks.EarlyStopping(patience=7) # 좀더 참다가 멈추어라
net.fit(X,y,epochs=200,batch_size=200,validation_split=0.2,callbacks=[cb1,cb2]) Epoch 1/200
240/240 [==============================] - 0s 1ms/step - loss: 0.7184 - accuracy: 0.7581 - val_loss: 0.5077 - val_accuracy: 0.8276
Epoch 2/200
240/240 [==============================] - 0s 890us/step - loss: 0.4752 - accuracy: 0.8386 - val_loss: 0.4793 - val_accuracy: 0.8342
Epoch 3/200
240/240 [==============================] - 0s 899us/step - loss: 0.4304 - accuracy: 0.8517 - val_loss: 0.4386 - val_accuracy: 0.8497
Epoch 4/200
240/240 [==============================] - 0s 880us/step - loss: 0.4048 - accuracy: 0.8582 - val_loss: 0.4029 - val_accuracy: 0.8603
Epoch 5/200
240/240 [==============================] - 0s 923us/step - loss: 0.3832 - accuracy: 0.8669 - val_loss: 0.3932 - val_accuracy: 0.8619
Epoch 6/200
240/240 [==============================] - 0s 934us/step - loss: 0.3697 - accuracy: 0.8705 - val_loss: 0.3842 - val_accuracy: 0.8657
Epoch 7/200
240/240 [==============================] - 0s 900us/step - loss: 0.3569 - accuracy: 0.8759 - val_loss: 0.3844 - val_accuracy: 0.8668
Epoch 8/200
240/240 [==============================] - 0s 889us/step - loss: 0.3482 - accuracy: 0.8774 - val_loss: 0.3679 - val_accuracy: 0.8708
Epoch 9/200
240/240 [==============================] - 0s 912us/step - loss: 0.3387 - accuracy: 0.8799 - val_loss: 0.3602 - val_accuracy: 0.8719
Epoch 10/200
240/240 [==============================] - 0s 923us/step - loss: 0.3299 - accuracy: 0.8820 - val_loss: 0.3610 - val_accuracy: 0.8748
Epoch 11/200
240/240 [==============================] - 0s 853us/step - loss: 0.3229 - accuracy: 0.8858 - val_loss: 0.3574 - val_accuracy: 0.8717
Epoch 12/200
240/240 [==============================] - 0s 904us/step - loss: 0.3157 - accuracy: 0.8873 - val_loss: 0.3572 - val_accuracy: 0.8743
Epoch 13/200
240/240 [==============================] - 0s 890us/step - loss: 0.3106 - accuracy: 0.8899 - val_loss: 0.3545 - val_accuracy: 0.8761
Epoch 14/200
240/240 [==============================] - 0s 911us/step - loss: 0.3046 - accuracy: 0.8914 - val_loss: 0.3493 - val_accuracy: 0.8759
Epoch 15/200
240/240 [==============================] - 0s 921us/step - loss: 0.3011 - accuracy: 0.8928 - val_loss: 0.3483 - val_accuracy: 0.8776
Epoch 16/200
240/240 [==============================] - 0s 937us/step - loss: 0.2988 - accuracy: 0.8935 - val_loss: 0.3733 - val_accuracy: 0.8716
Epoch 17/200
240/240 [==============================] - 0s 892us/step - loss: 0.2925 - accuracy: 0.8947 - val_loss: 0.3481 - val_accuracy: 0.8768
Epoch 18/200
240/240 [==============================] - 0s 933us/step - loss: 0.2880 - accuracy: 0.8951 - val_loss: 0.3396 - val_accuracy: 0.8801
Epoch 19/200
240/240 [==============================] - 0s 957us/step - loss: 0.2827 - accuracy: 0.8982 - val_loss: 0.3439 - val_accuracy: 0.8798
Epoch 20/200
240/240 [==============================] - 0s 881us/step - loss: 0.2791 - accuracy: 0.8986 - val_loss: 0.3489 - val_accuracy: 0.8779
Epoch 21/200
240/240 [==============================] - 0s 886us/step - loss: 0.2765 - accuracy: 0.9007 - val_loss: 0.3350 - val_accuracy: 0.8823
Epoch 22/200
240/240 [==============================] - 0s 912us/step - loss: 0.2709 - accuracy: 0.9016 - val_loss: 0.3350 - val_accuracy: 0.8812
Epoch 23/200
240/240 [==============================] - 0s 908us/step - loss: 0.2688 - accuracy: 0.9029 - val_loss: 0.3374 - val_accuracy: 0.8820
Epoch 24/200
240/240 [==============================] - 0s 930us/step - loss: 0.2658 - accuracy: 0.9041 - val_loss: 0.3445 - val_accuracy: 0.8805
Epoch 25/200
240/240 [==============================] - 0s 872us/step - loss: 0.2607 - accuracy: 0.9058 - val_loss: 0.3383 - val_accuracy: 0.8822
Epoch 26/200
240/240 [==============================] - 0s 928us/step - loss: 0.2607 - accuracy: 0.9056 - val_loss: 0.3415 - val_accuracy: 0.8811
Epoch 27/200
240/240 [==============================] - 0s 927us/step - loss: 0.2576 - accuracy: 0.9068 - val_loss: 0.3402 - val_accuracy: 0.8814
Epoch 28/200
240/240 [==============================] - 0s 905us/step - loss: 0.2525 - accuracy: 0.9098 - val_loss: 0.3469 - val_accuracy: 0.8802<keras.callbacks.History at 0x7f1b24217a00>#
# 조기종료가 구현된 그림이 출력
# %tensorboard --logdir logs --host 0.0.0.0 하이퍼파라메터 선택
- 하이퍼파라메터 설정
from tensorboard.plugins.hparams import api as hpa=net.evaluate(XX,yy)313/313 [==============================] - 0s 859us/step - loss: 0.3803 - accuracy: 0.8704!rm -rf logs
for u in [50,5000]:
for d in [0.0,0.5]:
for o in ['adam','sgd']:
logdir = 'logs/hpguebin_{}_{}_{}'.format(u,d,o)
with tf.summary.create_file_writer(logdir).as_default():
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(u,activation='relu'))
net.add(tf.keras.layers.Dropout(d))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer=o,loss=tf.losses.categorical_crossentropy,metrics=['accuracy','Recall'])
cb3 = hp.KerasCallback(logdir, {'유닛수':u, '드랍아웃비율':d, '옵티마이저':o})
net.fit(X,y,epochs=3,callbacks=cb3)
_rslt=net.evaluate(XX,yy)
_mymetric=_rslt[1]*0.8 + _rslt[2]*0.2
tf.summary.scalar('애큐러시와리컬의가중평균(테스트셋)', _mymetric, step=1) Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.5255 - accuracy: 0.8180 - recall: 0.7546
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.3993 - accuracy: 0.8588 - recall: 0.8294
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.3648 - accuracy: 0.8698 - recall: 0.8443
313/313 [==============================] - 0s 830us/step - loss: 0.4063 - accuracy: 0.8545 - recall: 0.8286
Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.7744 - accuracy: 0.7503 - recall: 0.5797
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.5204 - accuracy: 0.8223 - recall: 0.7565
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4742 - accuracy: 0.8369 - recall: 0.7859
313/313 [==============================] - 0s 828us/step - loss: 0.4899 - accuracy: 0.8304 - recall: 0.7831
Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.7502 - accuracy: 0.7356 - recall: 0.6115
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.5738 - accuracy: 0.7923 - recall: 0.7133
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.5473 - accuracy: 0.8037 - recall: 0.7321
313/313 [==============================] - 0s 865us/step - loss: 0.4319 - accuracy: 0.8448 - recall: 0.7919
Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 1.0932 - accuracy: 0.6228 - recall: 0.3971
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.7616 - accuracy: 0.7388 - recall: 0.5956
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.6828 - accuracy: 0.7684 - recall: 0.6478
313/313 [==============================] - 0s 894us/step - loss: 0.5265 - accuracy: 0.8180 - recall: 0.7353
Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4777 - accuracy: 0.8292 - recall: 0.7890
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.3603 - accuracy: 0.8682 - recall: 0.8427
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.3197 - accuracy: 0.8817 - recall: 0.8605
313/313 [==============================] - 0s 846us/step - loss: 0.3803 - accuracy: 0.8628 - recall: 0.8428
Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.6685 - accuracy: 0.7883 - recall: 0.6444
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4815 - accuracy: 0.8372 - recall: 0.7781
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4408 - accuracy: 0.8498 - recall: 0.8021
313/313 [==============================] - 0s 859us/step - loss: 0.4634 - accuracy: 0.8390 - recall: 0.7962
Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.5708 - accuracy: 0.7991 - recall: 0.7556
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4418 - accuracy: 0.8393 - recall: 0.8057
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4091 - accuracy: 0.8514 - recall: 0.8211
313/313 [==============================] - 0s 850us/step - loss: 0.3937 - accuracy: 0.8587 - recall: 0.8238
Epoch 1/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.6930 - accuracy: 0.7752 - recall: 0.6338
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.5048 - accuracy: 0.8274 - recall: 0.7651
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4608 - accuracy: 0.8417 - recall: 0.7910
313/313 [==============================] - 0s 854us/step - loss: 0.4625 - accuracy: 0.8396 - recall: 0.7957#
#%tensorboard --logdir logs --host 0.0.0.0숙제
- 아래의 네트워크에서 옵티마이저를 adam, sgd를 선택하여 각각 적합시켜보고 testset의 loss를 성능비교를 하라. epoch은 5정도로 설정하라.
net = tf.keras.Sequential()
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(50,activation='relu'))
net.add(tf.keras.layers.Dense(50,activation='relu'))
net.add(tf.keras.layers.Dense(10,activation='softmax'))
net.compile(optimizer=???,loss=tf.losses.categorical_crossentropy,metrics=['accuracy','Recall'])